Vertical Slice Architecture gives you incredible speed and flexibility by organizing code around features instead of technical layers.
Each slice encapsulates all aspects of a specific feature, including the API, business logic, and data access.
When you implement each feature, the necessary code stays together in the same folder or file.
Many developers were adopting Vertical Slice Architecture because of the following benefits:
Changes are isolated to specific features, reducing the risk of unintended side effects.
Other developers and teams to work on different features independently.
You can use different technologies or approaches within each slice as needed (aka CQRS on steroids).
It's easier to navigate in the solution, as all the code for a specific feature stays together.
I have built many projects using N-Layered and Clean Architecture, and one of the biggest challenges I faced was too much abstraction.
These types of Architectures often result in you creating a lot of premature abstractions that tend to solve some future problems:
What if a database might change in the future
What if we need to replace a messaging or logging library
What if this, what if that...
That's why I liked the Vertical Slice Architecture approach from the start.
I finally have the freedom to get rid of many premature abstractions and have the actual implementation sit in my slices.
But this freedom comes with a challenge: you can end up with a lot of code duplication:
Two slices need similar validation logic.
Three features query the same database table.
Five handlers format dates the same way.
That's why some devs critique Vertical Slice Architecture, saying it violates the DRY principle and encourages the WET Principle (write everything twice).
I have built a few projects with Vertical Slice Architecture in the last few years, and I want to show you my pragmatic approach to managing duplication.
In this post, we will explore:
Why Vertical Slice Architecture Leads to Code Duplication
Detecting Code Duplication
How to Avoid Duplication in Database Concerns
How to Avoid Duplication in Infrastructure Concerns
How to Avoid Duplication in Business Concerns
How to Avoid Duplication in Application Concerns
Decision Framework When Addressing Code Duplication
Why Vertical Slice Architecture Leads to Code Duplication
In traditional layered architecture, you organize code by technical concerns: Controllers, Services, Repositories, and Models.
When you need to add a new feature, you touch multiple layers. You add a controller method, a service method, a repository method, and maybe a DTO.
This structure naturally pushes you toward reuse.
If two features need similar logic, you put it in a shared service.
If three features query the same table, you add a method to the repository.
Vertical Slice Architecture flips this approach.
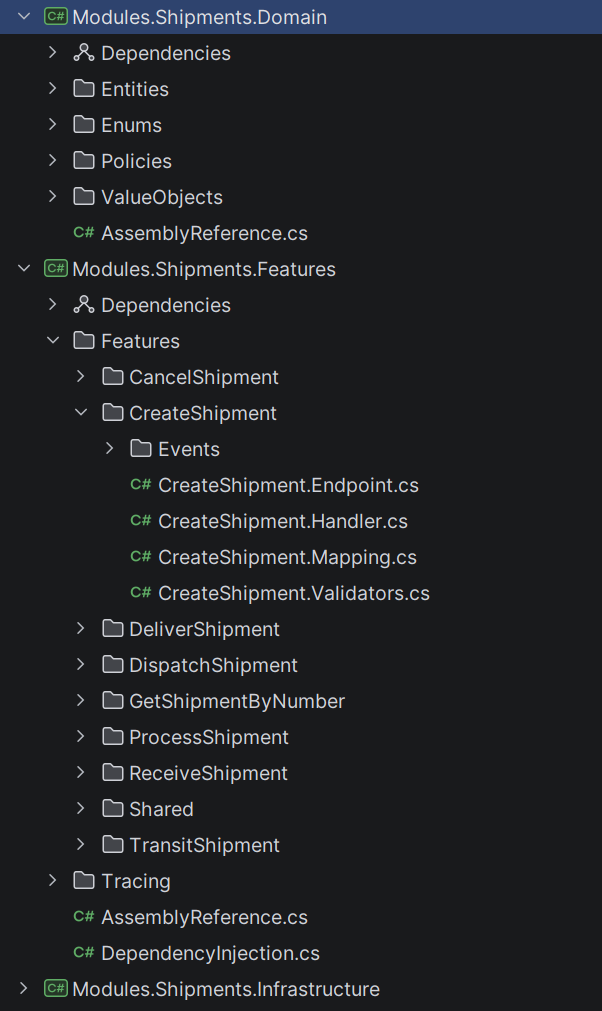
Each feature is a vertical slice that contains everything it needs: the endpoint, the handler, the validation, the data access, and the response model.
Here is what a typical VSA project structure looks like:
Each slice is independent. CreateShipment feature does not call GetShipmentByNumber and doesn't share code with other features.
This independence is the superpower of VSA. You can change one feature without worrying about breaking another.
But this independence also makes duplication visible.
If CreateShipment and ProcessShipment both need to validate that a product exists, you will write that validation twice.
But before addressing every code duplication case, you need to stop and think for a while.
Two pieces of code can look identical today and evolve in completely different directions tomorrow.
If you share them too early, you create coupling.
When one feature needs to change, you have to modify shared code that affects the other feature.
This is the cost of premature abstraction: you trade the flexibility to change one feature independently for the illusion of DRY code.
And the most important part is that most developers misunderstand DRY.
They think it's about removing duplicate code. It's not.
DRY is about duplicated knowledge, not the code.
Duplicate code is only a symptom. The real problem is duplicated business rules hiding across the system.
Here is where most teams get it wrong:
❌ They extract shared helpers too early.
❌ They create generic utilities that are hard to maintain
❌ They couple unrelated features just to reduce duplication.
This actually makes the code worse. Sometimes duplication is fine.
If two pieces of code change for different reasons, keep them separate.
This follows Single Responsibility better than forced reuse.
DRY is violated only when the same reason to change exists in multiple places.
Okay, enough theory.
Now, let's explore how we can avoid duplication and when and where we should extract shared code.
P.S.: if you use Dapper, then you should use Repositories.
I prefer not to use Repositories with EF Core, because EF Core's DbContext already implements the Repository and Unit of Work patterns, as stated in the official DbContext's code summary.
With Vertical Slices, I finally got free from using Repositories and started to use EF Core directly in the Application layer.
Using EF Core directly in the application use cases is a trade-off that gives me more advantages than disadvantages.
Yes, I can have some code duplicated across vertical slices.
But come on, having a single line of code in EF Core that queries an entity by ID across 3 slices is not a problem at all.
But when you have complex queries duplicated across multiple slices, it's time to extract the shared code.
You have the following options:
Extract the query into a shared class or method
Use extension methods, expression extensions for IQueryable
If you have a query that spans multiple aggregates, involves heavy filtering, sorting, or joins — and it's used across many features — wrapping it into a repository method can reduce duplication and centralize the logic.
If you select the extracted query, extension method or Specification options, you should decide where to put the shared logic.
You can:
Create a shared folder in the entity feature folder
Create a shared folder in the Infrastructure layer
In most cases, I would prefer a "Shared" folder in the entity feature folder.
If your shared logic belongs to a single entity, put it in the corresponding entity features folder.
For example, if you have a "Shipment" and "Tracking" entities, put the shared logic in the "Shipments" or "Trackings" folders.
If multiple entities use your shared logic, either extract it into a global "Shared" folder for all the features or create a shared folder in the Infrastructure layer.
Here are a few examples of extension methods for EF Core:
The Specification Pattern is a way to describe what data you want from your database using small, reusable classes called "specifications".
Each Specification represents a filter or a rule that can be applied to a query.
This lets you build complex queries by combining simple, easy-to-understand classes.
How to Avoid Duplication in Infrastructure Concerns
Besides the database access, you may have the following Infrastructure concerns:
Database Concerns
Logging
Caching
Event Messaging
Authentication
HTTP Client Configuration
Retry Policies
Health Checks
My take here is that technical infrastructure is usually safe to share in the Infrastructure layer.
Infrastructure code changes when you upgrade libraries or change technical decisions. These changes are rare and affect all features equally.
If your team prefers to add validation and caching to Repositories, then fine, you can do it.
But I prefer to keep the Infrastructure layer simpler, and I have moved some cross-cutting concerns to the Application layer, like: caching and logging.
I usually implement this using ASP.NET Core Middleware or pipelines around the application handlers.
Your Infrastructure layer could also have some helpful utility classes.
Here is an example of infrastructure code that is safe to share:
Business logic requires much deeper scrutiny.
It's directly related to the domain model and the business requirements.
Let's explore a few examples:
Order validation rules
Price calculation logic
Inventory management
Customer eligibility checks
Domain code changes when business requirements change. These changes are frequent and often affect only specific features.
If you share domain logic too early, you force all features to follow the same business rules even when requirements diverge.
Let me share a real example from a project I worked on.
We had two payment features: ProcessPayment and RefundPayment.
Both features had similar validation logic:
Check if the payment amount is positive
Validate the payment method
Verify the customer has sufficient funds
My team's first instinct was to create a shared PaymentValidator class.
But we decided to wait. We duplicated the validation in both slices.
Three months later, the business introduced a new requirement: refunds should allow negative amounts for partial refunds and skip the "sufficient funds" check.
If we had shared the validator, we would have needed to add conditional logic: "if this is a refund, skip this check". The shared validator would have become a mess of if-statements.
Because we duplicated the code, we simply changed the RefundPayment validation. The ProcessPayment validation remained untouched.
The validation logic seemed to be identical at first glance, but different as the application grew.
The best way to share business rules is to push them into entities, value objects or domain services.
Multiple vertical slices can share the same domain model.
This is where the Rich Domain Model from Domain-Driven Design comes in handy.
This allows logic like Shipment.CanBeCancelled() to live in one place while being used by CancelShipment and GetShipment slices.
Here is an example of a Shipment entity with business logic:
csharp
1// Domain/Shipments/Shipment.cs2publicsealedclassShipment3{4privatereadonlyList<ShipmentItem> _items =[];56publicGuid Id {get;privateinit;}7publicstring Number {get;privateset;}=null!;8publicstring OrderId {get;privateset;}=null!;9publicAddress Address {get;privateset;}=null!;10publicstring Carrier {get;privateset;}=null!;11publicstring ReceiverEmail {get;privateset;}=null!;1213publicShipmentStatus Status {get;privateset;}1415publicIReadOnlyList<ShipmentItem> Items => _items.AsReadOnly();1617publicDateTime CreatedAt {get;privateset;}18publicDateTime? UpdatedAt {get;privateset;}1920privateShipment(){}21publicstaticShipmentCreate(...){}2223publicboolCanBeCancelled()24{25return Status isShipmentStatus.Pendingor ShipmentStatus.Confirmed;26}2728publicboolCanBeShipped()29{30return Status == ShipmentStatus.Confirmed;31}3233publicResult<Success>Process(){}34publicResult<Success>Dispatch(){}35publicResult<Success>Deliver(){}36publicResult<Success>Receive(){}37publicResult<Success>Cancel(){}38}
Now both CancelShipment and GetShipment slices can use the same Shipment entity:
csharp
1// Features/Shipments/CancelShipment/CancelShipmentHandler.cs2publicclassCancelShipmentHandler3{4privatereadonlyShipmentDbContext _context;56publicasyncTask<Result>HandleAsync(Guid shipmentId,CancellationToken cancellationToken)7{8var shipment =await _context.Shipments.FindAsync(shipmentId, cancellationToken);9if(shipment isnull)10{11return Result.NotFound("Order not found");12}1314// Business logic is in the entity15 shipment.Cancel();1617await _context.SaveChangesAsync(cancellationToken);1819return Result.Success();20}21}
The business rule "a Shipment can only be cancelled if it is Pending or Confirmed" lives in the Shipment entity instead of being duplicated across multiple handlers.
This is safe sharing because the domain model represents the core business concepts that are stable across features.
Domain and Business logic can be pushed down into:
Domain entities (Shipment, Order, Payment)
Value objects (Money, Email, Address)
Entity base classes (if you use them)
Domain events
Common enums (Currency, Country)
When you genuinely need cross-feature shared logic, decide whether it is domain logic or infrastructure logic.
Domain Services contain business rules that span multiple features:
This creates coupling. Every handler inherits from BaseHandler. If you need to change or omit validation for one handler, you have to modify the base class or add conditional logic.
Another example of code duplication is using different DTOs across multiple handlers.
On one project, we built an e-commerce system with VSA. We had two features: GetProduct and SearchProducts.
Both features returned product information, so we created a shared ProductDto:
csharp
1// Shared/ProductDto.cs2publicrecordProductDto3{4publicGuid Id {get;init;}5publicstring Name {get;init;}6publicstring Description {get;init;}7publicdecimal Price {get;init;}8publicstring Currency {get;init;}9publicint StockQuantity {get;init;}10publicstring Category {get;init;}11publicList<string> Images {get;init;}12}
Both GetProduct and SearchProducts used this DTO.
Three months later, the business asked us to add a new field to the search results: "Average Rating".
But GetProduct did not need this field. It had its own detailed rating section.
We had two options:
Add AverageRating to ProductDto and make it nullable. Now GetProduct returns a field it does not use.
Create a new ProductSearchDto and duplicate most of the fields.
We chose option 2, but now we have two DTOs with 90% identical fields.
The lesson: DTOs are feature-specific. Even if they look identical today, they might diverge tomorrow.
If we had duplicated the DTO from the start, adding AverageRating would have been a one-line change in SearchProducts.
Decision Framework When Addressing Code Duplication
Vertical Slice Architecture does not necessarily break DRY.
It helps to avoid premature abstraction.
The main goal with Vertical Slice Architecture is not to eliminate duplication. The goal is to maintain the independence of your slices so that each feature can evolve without breaking others.
Use the following decision framework when avoiding duplication:
1. Prefer WET Principle at start (Write Everything Twice)
When you see the same code in two places, don't rush to extract it.
If you extract it too early, you risk creating the wrong abstraction.
If three or more slices depend on the same code, then it's time for extraction.
Wait until you have enough data to see the real pattern.
2. Query the database directly
Each slice should own its data access. Do not call other slices to get data. Query the database directly and select exactly what you need.
If needed, extract repeated logic into a shared class, an extension method, a specification, or a Repository (as a last resort).
3. Share Infrastructure concerns
Technical infrastructure is safe to share across all slices.
Cross-cutting concerns like logging, caching, message queues, authentication, health checks, and telemetry should be centralized in the Infrastructure layer.
Also, extract utilities like Clock, IdGenerator, Pagination, Hashing, and JsonOptions into the Infrastructure layer.
These change when you upgrade libraries, not when business requirements change.
These concerns are purely technical and have no business meaning.
They affect all features equally and change only when you upgrade libraries or modify technical decisions.
4. Push Business logic into Domain Model
Share business rules through entities, value objects, and domain services.
Logic like Shipment.CanBeCancelled() or Money.Add() belongs in the domain model, do not duplicate it across handlers. This is the safest way to share business rules.
5. Extract capabilities, not workflows
Share reusable capabilities like IEmailSender, IBlobStorage, or IPdfRenderer.
Keep workflows (business processes) such as CreateInvoice or ProcessOrder within their respective slices.
Capabilities are technical and stable. Workflows are business-specific and change frequently.
6. Use Composition over Inheritance
Avoid base handler classes that create hidden coupling. Instead of inheriting from BaseHandler, inject small services explicitly.
This keeps handlers independent and easier to change.
7. Features must own their Request/Response models
Don't share DTOs between slices. Even if they look identical today, they might diverge tomorrow. Each feature should have its own models.
8. Prioritize changeability over DRY
The ultimate goal is to create a system where code is easy to change when business requirements evolve. If duplication makes your code easier to change, embrace it.
Vertical Slice Architecture gives you the freedom to move fast and change features independently. But this freedom requires discipline.
9. Enforce your code design with architecture tests
Use ArchUnitNET to write architecture tests that verify slices do not reference each other.
You can also write tests to ensure that some classes are not shared between slices.
Follow the patterns in this article, and you will build a system that is both flexible and maintainable.
If you want to learn more about Vertical Slice Architecture, check out my other articles:
Hope you find this newsletter useful. See you next time.
Whenever you're ready, here's how I can help you:
The .NET Senior Playbook is built to:
Fast-track you from junior or mid-level to senior
Keep you growing as a senior
Help you beat any .NET interview
Covers everything: C#, ASP.NET Core, EF Core, system design — answer each question first, reveal the solution, and a test after every chapter proves it stuck. Finish, and you earn a verifiable certificate for your LinkedIn.
Not sure where you stand? Take the free .NET Interview Run:
Find out your real level — Junior to Senior+
A realistic mock .NET interview — across 13 areas of C#, .NET, ASP.NET Core and System Design
No credit card required. When you finish, you get a personalized report: your level, your strongest and weakest areas, and where to focus next — the perfect way to benchmark yourself before diving into the Playbook.